/r/dailyprogrammer_ideas


This subreddit is purely dedicated to accepting challenges and suggestions for the subreddit /r/dailyprogrammer.
Welcome to /r/DailyProgrammer challenge submissions! The focus of r/DailyProgrammer is to provide daily/weekly challenges to keep your mind and fingers busy between projects. This subreddit (r/DailyProgrammer_Ideas) is a challenge submission system, where you can submit any ideas, which may be accepted and posted to the official subreddit! We normally post Easy challenges on Mondays, Intermediate on Wednesdays, and Hard on Fridays. Once your submission is peer reviewed and accepted, we will put it into the challenge rota and post it shortly.
Submission Procedure
There are minimum criteria you must meet for submitting a good challenge:
Your post title must start with [Easy|Intermediate|Hard] and the title, and be written in a clear format with at least good English skills.
Challenges should be described in a fun and lighthearted manner, even if the challenge itself is conceptually difficult.
A good format for the description would be two to three short paragraphs: a general background, a detailed explanation of the task, and a final example walk-through.
Challenges should ideally be easy to describe and without the need of specialized knowledge outside of programming. If a developer cannot research and understand any knowledge-dependencies (outside of general programming) in a few minutes, then your challenge might be too specialized of a topic.
Make the title interesting; it does not have to explicitly say what you are doing in the challenge.
Set the difficulty to an appropriate level. Easy challenges have trivial brute-force solutions or require no complex logic. Intermediate challenges may have some sorting and searching involved, and though can be solved through brute-force, are too complex to solve without algorithms and some clever thinking. Hard challenges require knowledge and control over a programming language, good logic skills and creativity.
What you must fill out in your post is the following:
Difficulty and Title
Challenge Description
Input Description
Output Description
Sample Input data
Sample Output data
Extension challenges (optional)
Notes and Further Reading (optional)
This is the kind of format you want to mimic. Of course, if your challenge can't be easily formatted like the above, feel free to use your own formatting. Challenges which deviate too far from these rules might not be submitted, however.
Questions or comments? Feel free to message the mods!
/r/dailyprogrammer_ideas
4,098 Subscribers
Silly Music Sorting Idea
Hi new friends, Idea I had because I am a nerd about how I listen to music. Very impractical, but very interesting to me. Please point me in the right direction if this doesn't fit here.
How would you approach finding the most appealing and least appealing songs by a band mathematically? If the only data set you had was number of total plays (cumulative) on the particular day you approach the problem (like the Spotify play count), and you were looking at a discography for a not-super-famous artist that spanned multiple albums over a long period of time.
The play count itself is a measurement of this in a way, but there are known biases that are simply not addressed if you just used those numbers. Biases that should be addressed are as follows: Time available: the longer the track has been available, the bigger the playcount from passive album plays. First Track Bias: A person enjoys a single, decides to go check out the album. People tend to decide after track one if they want to listen to the other non singles or not, so we see a big drop off but the first track generally has a much higher play count then other non-singles. Later Track Bias: Similarly, people tend to drop off at different times in a passive album listen of any kind. The later the track, the fewer listens. I haven't mapped the stats here specifically, but I am betting it's not a straight slope but I bet it would be parabolic or some kind of third degree curve. Single Bias: Singles get a lot more attention just because they are shared around more promotional effort. Featured in or Featuring Bias: people love another thing, and when a new artist gets connected to that thing they like it more than they might have liked that artist on its own. This can be when a song is featured in a movie (or commercial, tv show, video game) or when two artists work together on a song. Meta Bias: We can't forget that artists and producers ARE actively aware of these biases. Album order is usually quite intentional but not always in the conventional way. Some artists, for example, will start an album with a bunch of non-singles, and then bury the singles in the last half of the album. It is not unheard of but it is very surprising to an analytic listener. But the conventional way to order an album comes from understanding that the first track needs to hook a listener without being a single, then singles are sprinkled throughout the front half (ish) of the album while more esoteric stuff is dropped in the back because listeners are likely to have dropped off either way at this point. Popularity bias: the numbers must be relative to the artist only, not relative to other artists. Finally, an artists best and worst songs simply aren't likely to be right next to each other in number of plays. There is likely some sort of bell curve for every artist that has outstandingly successful and outstandingly unsuccessful songs, with a large chunk of chaff in the middle. If this sort of bell curve is the goal, how would you mathematically go about attempting to sort this data while accounting as best you can for the mentioned biases? Are there other biases I left out you think are important? Would you reword any of this to be more accurate to the goal and function?
Thanks.
18:27 UTC
Launched My First SaaS Boilerplate/Starter Kit: HTML/CSS Extractor – Check It Out!
Hey everyone!
I’ve been working on something that I’m really excited to share with you all. It’s a Saas starter boilerplate designed as an HTML/CSS extractor. If you’re into building web tools or need a solid starting point for a project, this might be just what you’re looking for.
Here’s what it includes:
- Easily extracts HTML and CSS from any element on a webpage.
- Built with React and Flask, with Firebase for the db, stripe for handling payments, and Mailgun for sending emails.
- It’s deployment-ready! Backend to Heroku, frontend to Render .
I’ve also added some cool features and growth ideas, like connecting it with chatGPT for realtime code edits or converting the extracted code into Figma designs. It’s meant to be a solid foundation for anyone looking to build or expand their own Saas product.
If this sounds like something you could use, or if you know someone who might be interested, feel free to check it out.
Here’s the link: https://linktr.ee/SaasBoilerplates1
19:14 UTC
Fun programming challenge: figure out which sets of passports grant visa-free access to the whole world
Hey there,
I wanted to know which sets of passports grant together visa-free access to every country in the world, but I could not easily find that info online. So I figured that I could try to write a small program to determine these sets of passports myself, and then it occurred to me that it would probably be a fun programming challenge to organize. Would this challenge be a good fit for /r/dailyprogrammer ?
Here's the challenge.
- Scrape the data you need for instance from The Henley Passport Index.
- Design a clever algorithm to efficiently find out which are the smallest sets of passports that will grant you visa-free access to every country in the world.
- Optional. Allow the user to specify which passports they already hold and find out which sets of passports would complement their passports well.
- Optional. Rank the sets of passports by how easy it is to acquire citizenship in those countries.
Feel free to share your own twists to the challenge that could make it even more fun & interesting.
09:48 UTC
What's the best way to fit rectangles inside an irregular quadrilateral while avoiding objects?
Description
Let's say you have an area of land that's an irregular quadrilateral. Let's say that land has 5 trees on it, within the quadrilateral. Then, let's say you want to find 5 rectangles that will become gardens, such that the sum total of area inside rectangles is as large as possible.
The rectangles cannot contain trees. The rectangles cannot overlap.
Formal Inputs & Outputs
What you know: The 4 points that define the quadrilateral; the points that define the centres of trees, and the diameter of each tree (trees are modelled as circles).
What you want: the description of 5 rectangles that fit inside the quadrilateral completely, that don't overlap with each other, and that don't contain any trees. The sum total area of the rectangles will be your score. Whoever has the highest score, wins.
Input description
These are the points that will define the quadrilateral:
{ { 1015, 170 }, { 1014, 47 }, { 1093, 117 }, { 1069, 176 } }
These are the points that define the centres of the trees:
{ { 1065, 172 }, { 1036, 145 }, { 1054, 128 }, { 1078, 124 }, { 1037, 100 } }
These are the diameters of those 5 trees:
{ 3.3, 11.3, 11.3, 6.7, 15.7 }
Output description
Description of the rectangles, and the sum total area of those rectangles.
Description of a rectangle should be expressed as the bottom-left point along with a height and a width.
Notes/Hints
This is a packing problem with a twist: the objects (trees) that you have to avoid, and the irregular quadrilateral.
Here's the best solution I've found so far:
{kind=link}
02:05 UTC
Pretty formater for markdown tables
Description
Tables aren't part of the core Markdown spec, but they are part of GFM and Markdown Here supports them. They are an easy way of adding tables to your email -- a task that would otherwise require copy-pasting from another application.
For instance
Colons can be used to align columns.
| Tables | Are | Cool |
| ------------- |:-------------:| -----:|
| col 3 is | right-aligned | $1600 |
| col 2 is | centered | $12 |
| zebra stripes | are neat | $1 |
There must be at least 3 dashes separating each header cell.
The outer pipes (|) are optional, and you don't need to make the
raw Markdown line up prettily. You can also use inline Markdown.
Markdown | Less | Pretty
--- | --- | ---
*Still* | `renders` | **nicely**
1 | 2 | 3Turns into
Colons can be used to align columns.
| Tables | Are | Cool |
|---|---|---|
| col 3 is | right-aligned | $1600 |
| col 2 is | centered | $12 |
| zebra stripes | are neat | $1 |
There must be at least 3 dashes separating each header cell. The outer pipes (|) are optional, and you don't need to make the raw Markdown line up prettily. You can also use inline Markdown.
| Markdown | Less | Pretty |
|---|---|---|
| Still | renders | nicely |
| 1 | 2 | 3 |
As we do not have to input tables nicely, our goal is to fix this. This means:
- Align its contents and return the formatted tables. The content in right aligned columns should be right aligned, contents in centered columns should be centered.
For even columns should be left centered. So 'XOXX' instead of XXOX where X denotes space and O content.
- The tables should as small as possible to fit all the content.
- Tables should have outwards facing pipes meaning
| foo | bar |instead offoo | bar. - Every column should have 1 space of padding meaning
|foo|bar|becomes| foo | bar |.
Input & Output
Take in a multiline string, a string or a md file containing a single markdown table
Examples:
Input
|Markdown|Less|Pretty|
|:-|:-|:-|
|*Still*|`renders`|**nicely**|
|1|2|3|Output
| Markdown | Less | Pretty |
| -------- | --------- | ---------- |
| *Still* | `renders` | **nicely** |
| 1 | 2 | 3 |Input
test|foo
bar|bazOutput
| test | foo |
| bar | baz |Input:
item | test
------|:-----:
test2 | lolOutput:
| item | test |
| ----- | :---: |
| test2 | lol |Input
|item|shorter|longtitle|
|:-|:-|:-|
|test2|t3|text|Output
| item | shorter | longtitle |
| ----- | :-----: | --------: |
| test2 | t3 | text |Input
| Task | Time required | Assigned to | Current Status | Finished |
|----------------|:-------------:|---------------|----------------|----------:|
| Calendar Cache | > 5 hours | | in progress | - [x] ok?
| Object Cache | > 5 hours | | in progress | [x] item1<br/>[ ] item2
| Object Cache | > 5 hours | | in progress | <ul><li>- [x] item1</li><li>- [ ] item2</li></ul>
| Object Cache | > 5 hours | | in progress | <ul><li>[x] item1</li><li>[ ] item2</li></ul>Output
| Task | Time required | Assigned to | Current Status | Finished |
| -------------- | :-----------: | ----------- | -------------- | ------------------------------------------------: |
| Calendar Cache | > 5 hours | | in progress | - [x] ok? |
| Object Cache | > 5 hours | | in progress | [x] item1<br/>[ ] item2 |
| Object Cache | > 5 hours | | in progress | <ul><li>- [x] item1</li><li>- [ ] item2</li></ul> |
| Object Cache | > 5 hours | | in progress | <ul><li>[x] item1</li><li>[ ] item2</li></ul> |Notes/Hints
If no alignment is given, the default markdown alignment is left.
Extra
Take a markdown file as input, return the markdown file with all of its tables formatted, but leave the rest of the file intact.
11:07 UTC
Find the minimum number of walls to add such that no path exists between A and B.
Hey, I have a suggestion for a coding interview I had recently that I haven't been able to find anywhere else. I thought it's a good problem as it's easy to look at but hard (imo) to solve.
The question goes like so (paraphrased):
Given an N x M grid map where:
"A" and "B" are arbitrarily placed points of interest
"." is a path
"#" is an existing wall
"@" is a wall added by the solution (purely for visual clarity)
Write a solution to find the minimum number of "@"s to add such that there is no path between A and B.
The directions of movement are up down left right, no diagonals.
If no such walls can be added (i.e. A and B are immediately adjacent) then return -1
Optionally print the new map with the added walls.
DO NOT simply surround A or B. It may be a potential solution (eg. example 2), but is definitely the wrong approach for a general solution (eg. examples 3, 4).
The first line of input is simply to inform your solution of the size of the incoming grid, given as n_rows n_cols.
Example input 1
3 4
....
.AB.
....answer = -1
because: A and B are already touching, no wall can be added to block the path
Example input 2
5 4
....
.A..
....
..B.
....answer = 4
because:
....
.A..
@@@@
..B.
....
or
.@..
@A@.
.@..
..B.
....
and moreExample input 3
5 4
.A..
....
.##.
....
..B.answer = 2
because:
.A..
....
@##@
....
..B.
or
.A..
@...
.##.
...@
..B.
and moreExample input 4
8 8
.......#
.A......
.....#..
....#...
...#....
..#.....
......B.
........answer = 3
because:
.......#
.A....@.
.....#..
....#...
...#....
..#.....
..@...B.
..@.....
or
.......#
.A....@.
.....#..
....#...
...#....
.@#.....
@.....B.
........
or
.......#
.A....@.
.....#..
....#...
...#....
..#.....
.@....B.
@.......
and moreI was given 2 hours to come up with a solution. I failed miserably and struggled with search algorithms and whatnot before settling with the "entombing" method of just surrounding A or B, whichever required fewer walls, and checking if A and B are adjacent for the -1 cases. I got 50% of the test cases.
If anyone has a name for this algorithm please let me know because my google skills aren't up to the task.
14:26 UTC
[easy?] Sorting scanned pages
Description
As a side project, a handful of us are scanning manuals to preserve documentation. Unfortunately, no software seems able to properly rename/renumber pages when they are individually scanned from booklets that are stapled and folded in the middle.
Formal Inputs & Outputs
Input description
A bunch of files are created ending in _01, _02, _03.tif, etc. You always end up with an even number since you are scanning the front and back of a page. "Page_01.tif" contains the back of the booklet and the front cover, so a simple 3 sheet book, stapled and folded in the middle, makes 6 scans consisting of 12 (original) pages we are attempting to recreate. Titles can contain punctuation and spaces, so needs to accommodate something like "Me & Mr. McGee - The Continuing Adventures (USA)_01.tif"
Example file set:
Adventure Island (USA)_01.tif
Adventure Island (USA)_02.tif
Adventure Island (USA)_03.tif
Adventure Island (USA)_04.tif
Adventure Island (USA)_05.tif
Adventure Island (USA)_06.tif
Adventure Island (USA)_07.tif
Adventure Island (USA)_08.tif
Output description
Two subdirectories (called "Left" and "Right") exist that we use Photoshop actions on to crop 55% to the respective side so we can go back and crop to the exact page size later. So for our three sheet, 12 page "Page_01.tif" example, the front cover ("Page_01.tif"- right half of the scan) ends up in the "Right" subdirectory, and a copy renamed to "Page_12.tif" (left half of the scan) ends up in the "Left" subdirectory
"Page_01.tif" needs to be *copied* to a subdirectory called "Left" and renamed "Page_12.tif" and *moved* to a subdirectory called "Right" (It remains "Page_01.tif).
"Page_02.tif" needs to be *copied* to a subdirectory called "Right" and renamed "Page_11.tif" and *moved* to a subdirectory called "Left" (It remains "Page_02.tif).
"Page_03.tif" needs to be *copied* to a subdirectory called "Left" and renamed "Page_10.tif" and *moved* to a subdirectory called "Right" (It remains "Page_03.tif).
"Page_04.tif" needs to be *copied* to a subdirectory called "Right" and renamed "Page_09.tif" and *moved* to a subdirectory called "Left" (It remains "Page_04.tif).
"Page_05.tif" needs to be *copied* to a subdirectory called "Left" and renamed "Page_08.tif" and *moved* to a subdirectory called "Right" (It remains "Page_05.tif).
"Page_06.tif" needs to be *copied* to a subdirectory called "Right" and renamed "Page_07.tif" and *moved* to a subdirectory called "Left" (It remains "Page_06.tif).
6 scans is easy, but more common are 12, 16, and 20+, so it needs to run through all available pages until they are all correctly renamed/moved.
Visual Example:
http://www.atensionspan.com/Example.jpg
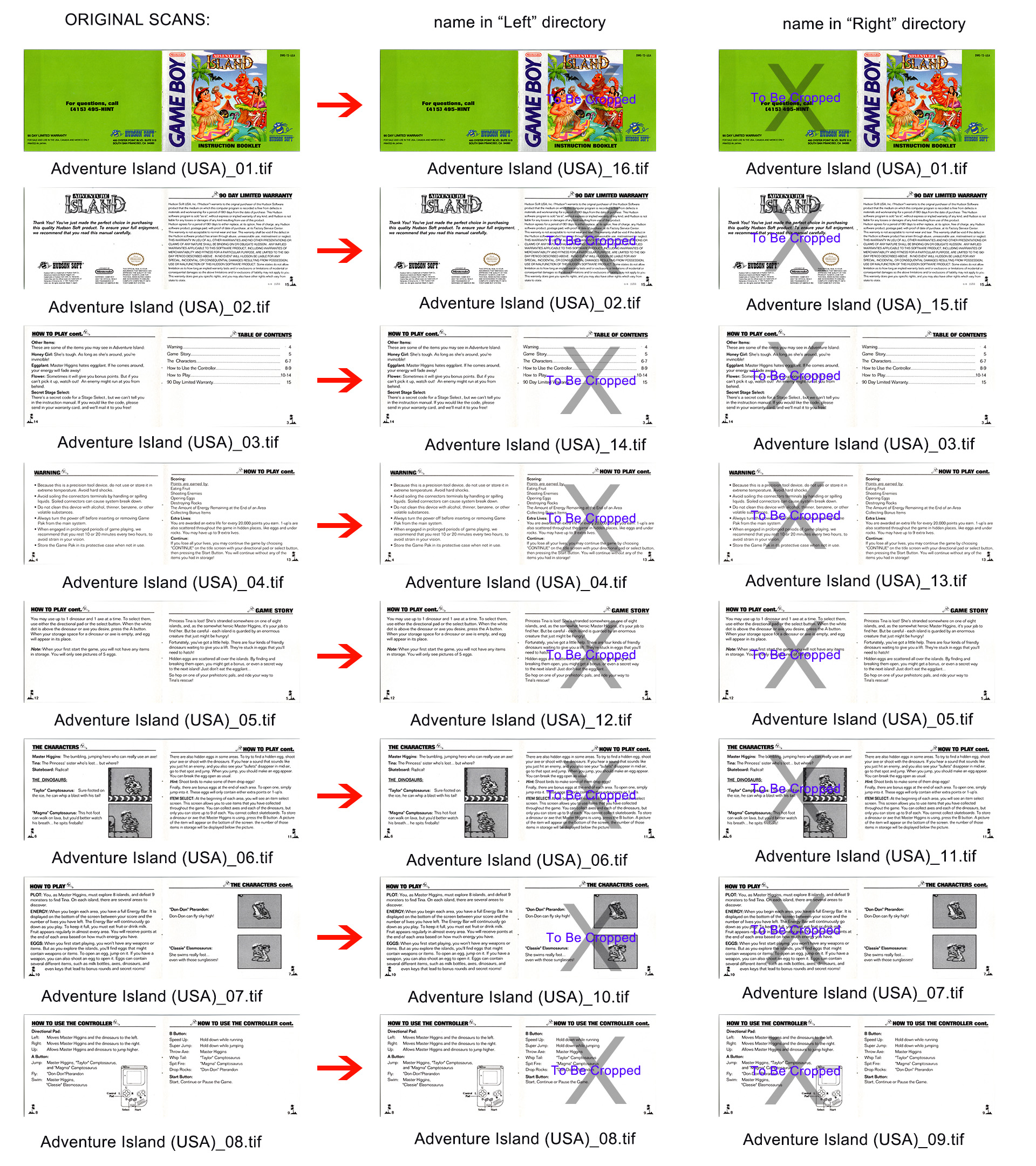{kind=link}
**Difficulties include**: you need to figure out the highest number scan in a set and double that number to create the countdown cadence. So say you have a set ending with "This manual (USA)_16.tif", your "This Manual (USA)_01.tif" will be split into "This manual (USA)_32.tif" (the back cover- which is 2x16 scans) and "This Manual (USA)_01.tif" (the front cover).
Also, thick books run us into 3 digits. So say your initial set ends with "Thicc Manual (USA)_64.tif", then you start out with"Thicc Manual (USA)_01.tif" being turned into "Thicc Manual (USA)_128.tif" and "Thicc Manual (USA)_001.tif" <- now you have to push the whole set out to 3 digits.
Notes/Hints
Page_##; Left_page #; Right_page #
Page_01=2x total, 01
Page_02=02, 2x total-1
Page_03=2x total-2, 03
Page_04=04, 2x total-3 etc, until you run out of pages
If the number of scans is 50 or greater, needs to convert output to 3 digit numbering.
Here is the current .bat file for moving/renaming 10 scans/20 pages:
~~~
copy "*_01.tif" .\Left\"*_20.tif"
move "*_01.tif" .\Right\
copy "*_03.tif" .\Left\"*_18.tif"
move "*_03.tif" .\Right\
copy "*_05.tif" .\Left\"*_16.tif"
move "*_05.tif" .\Right\
copy "*_07.tif" .\Left\"*_14.tif"
move "*_07.tif" .\Right\
copy "*_09.tif" .\Left\"*_12.tif"
move "*_09.tif" .\Right\
copy "*_02.tif" .\Right\"*_19.tif"
move "*_02.tif" .\Left\
copy "*_04.tif" .\Right\"*_17.tif"
move "*_04.tif" .\Left\
copy "*_06.tif" .\Right\"*_15.tif"
move "*_06.tif" .\Left\
copy "*_08.tif" .\Right\"*_13.tif"
move "*_08.tif" .\Left\
copy "*_10.tif" .\Right\"*_11.tif"
move "*_10.tif" .\Left\
~~~
Bonus
While I'm okay with copying over an individual scan set and running the program to sort and rename, in a perfect world the program should be able to sort through a directory of say 700 unique titles comprised of 6 to 86 scanned pages for each title.
04:06 UTC
5 Friends (let's call them a, b, c, d and e) are playing a game and need to keep track of the scores. Each time someone scores a point, the letter of his name is typed in lowercase. If someone loses a point, the letter of his name is typed in uppercase. Give the resulting score from highest to lowes
import java.util.*;
import java.util.Map.Entry;
public class FiveFriends {
public static Map<Character,Integer> map= new HashMap();
static void tracing(Map<Character,Integer> map,String name) {
boolean flag=false;
for (int i = 0; i < name.length(); i++) {
Set key=map.entrySet();Iterator itr=key.iterator();
while (itr.hasNext()) {
Map.Entry object = (Map.Entry) itr.next();
if((Character) object.getKey()==name.charAt(i)) {
if(flag) {
int x=(Integer)object.getValue();
object.setValue(x-1);
}
else {
int x=(Integer)object.getValue();
object.setValue(x+1);
}
}
else if((Character) object.getKey()==Character.toLowerCase(name.charAt(i))) {
int x=(Integer)object.getValue();
object.setValue(x-1);
}
}
}
}
public static void main(String\[\] args) {
map.put('a',0);
map.put('b',0);
map.put('c',0);
map.put('d',0);
map.put('e',0);
String input="dbbaCEDbdAacCEAadcB";
//String input="abcde";
tracing(map,input);
System.out.println(map);
}
}23:30 UTC
Probability for blackjack [medium]
- Calculate the odds of getting 21 in blackjack with 5 cards exactly, by making a program that simulates a real blackjack game accurately enough. Make this as time-efficient as possible, so it can run many times and get a more accurate result.
Rules: You continue drawing cards until you exceed 21 (dead) or reach 21 points. Ace is worth either 11 or 1. 2-10 is worth their value and jack, queen and king are worth 10.
- Calculate the odds of getting 21 for each number of cards drawn. (Instead of just 5, calculate the odds for 2 through 11.
Inspired by this r/theydidthemath request: https://www.reddit.com/r/theydidthemath/comments/out2j4/request_odds_of_getting_21_in_blackjack_with_5_or/?utm_medium=android_app&utm_source=share
I answered it in the comments of this post (I hope correctly).
I hope this is clear enough, otherwise please ask for clarification.
23:57 UTC
Variable Length Binary Integer's
Imagine for a moment you were just hired by an IoT developer. To facilitate variable length packets the IoT MQTT protocol defines something called a Variable Length Integer.
The Variable Length Integer is encoded using an encoding scheme which uses a single byte for values up to 127. Larger values are handled as follows:
The least significant seven bits of each byte encode the data, and the most significant bit is used to indicate whether there are bytes following in the representation. Thus, each byte encodes 128 values (0-127) and a "continuation bit".
The maximum number of bytes in the Variable Byte Integer field is four.
The encoded value MUST use the minimum number of bytes necessary to represent the value
- Your assignment is to write a function to read a variable length integer from the stream and return it's value as an integer. The integer should not exceed 32 bits, or an exception should be indicated.
- Additionally you need to write a procedure that when passed an integer, will encode it as a variable length integer and send it to the stream.
EDIT: to add:
Size of Variable Byte Integer
Digits From To
1 0 (0x00) 127 (0x7F)
2 128 (0x80, 0x01) 16,383 (0xFF, 0x7F)
3 16,384 (0x80, 0x80, 0x01) 2,097,151 (0xFF, 0xFF, 0x7F)
4 2,097,152 (0x80, 0x80, 0x80, 0x01) 268,435,455 (0xFF, 0xFF, 0xFF, 0x7F)
03:22 UTC
[Intermediate] - Floor Designer
Flooring Design Question
Imagine for a moment that you work for a flooring company. You’ve been laying hardwood floors for a while and you find yourself in a rather peculiar situation. To your surprise, Eric, your coworker with the only saw has left and has taken the saw with him. You look at the scrap pile of hardwood that remains and you find the following pieces.
| Quantity | Length(cm) | Height(cm) |
|---|---|---|
| 10 | 90 | 10 |
| 10 | 45 | 10 |
| 20 | 22.5 | 10 |
| 20 | 8 | 10 |
You’re determined to lay the hardwood flooring in the last room of the customers home, and agree to finish the job. The room that you’re going to be flooring has the dimensions of 196cm x 100cm.
The customer heard that you were a great programmer, and requested a script that would do the following:
- Use no more materials than you found in the scrap pile (the customer is environmentally conscious)
- Output a visual of the completed room, which will include a grid of what size pieces are used in a particular row.
- Bonus points if each execution of the script produces different results (within possibility).
Example result: https://x0.at/AQ9.png
{kind=link}
Notes:
- Let’s assume greater-than-human precision is at play, and there are no imperfections in the room, wood, etc.
16:27 UTC
Unpachinko [Medium]
Edit: Many thanks to /u/bpdolson, who points out that this problem is not uniquely solvable as posed. Please ignore it unless you want to try to salvage it somehow. Ah well.
Description
A Pachinko machine is a gambling device. A bunch of small balls are dropped from the top, bounce off pins, and land at slots in the bottom.
Our idealized Pachinko machine looks roughly like this:
o
*
* *
* * *
* * * *
| a| b| c| d| e| f| g| h|The ball o falls and hits the first pin * and bounces either left or right with some probability. It then falls and hits one of the second-row pins, again falling left or right, and so forth until it lands in one of the bins a…h. (The last pin will send the ball into one of the two bins immediately below it.)
Now a perfect Pachinko machine's pins would be equally likely to send the ball left or right. Our machine isn't so good. Let's call the probability that a given pin p sends the ball left p[l], and the probability that it goes right p[r] = 1 - p[l].
Imagine that you see such a Pachinko machine with N bins, where N is a power of two. The machine has been running for a while, and there are a bunch of balls in most of the bins. You count the balls in each bin. Assume that these counts represent the true probability distribution obtained by dropping an arbitrary number of balls (unlikely!).
Question: What is p[l] for the topmost pin?
Input
An array of ball counts. The array will be some length that is a power of 2.
Output
The probability that the topmost pin p[l] sends the ball left.
I haven't actually solved this, so who knows how difficult it is? I have a pretty good idea how to: >! You can figure the probabilities for the bottom row of pins and leftmost diagonal of pins pretty easily — you've now reduced the problem to a smaller problem !<. The code is likely to be a bit windy and require some interesting data structure.
05:39 UTC
Fuelling Cars Challenge
[ Removed by reddit in response to a copyright notice. ]
10:01 UTC
Knuth Conjecture
#Description
Knuth conjectured that, any positive integer could be computed starting with the number 3 and performing a sequence of factorial, square root, or floor operations. For example, we can compute 26 as:
floor(sqrt((3!)!)) = 26#Input
A positive integer: 26
#Output
The sequence of operations to produce the input integer: floor(sqrt((3!)!))
22:11 UTC
[Easy] National Holidays
I was given this task at work a little while ago, and I thought it might make an interesting challenge for beginners.
##Description
In the United States, there are a number of days which are designated “National Holidays.” On these holidays, many business close early or entirely. This year, you’ve been told to make the company calendar, but there’s a new twist to it: your office will be closed on all national holidays.
Unfortunately, national holidays rarely have a fixed date: they instead will often be on the Xth weekday of month Y.
You now need to write a script which checks a given date to see if it’s a national holiday and returns a simple boolean. This can then be fed into your other programs to dictate what runs (or doesn’t) on those days.
##Inputs
An arbitrary day in any form of your choice: strings and long integers are common ways to input dates for many languages.
You also have a list of national holidays:
- Mother’s Day is the second Sunday in May.
- Memorial Day is the last Monday in May.
- Father’s Day is the third Sunday in June.
- Labor Day is the first Monday in September.
- Thanksgiving is the fourth Thursday in November.
This list does not include holidays with fixed dates (Like Christmas on December 25th) or other odd holidays like Easter (where you need to consult a lunar phase chart or something); let somebody else worry about those.
##Output
A simple boolean which is Trueif the input date is a holiday. Optionally, you can also have it return the name of the holiday.
Notes
One way to make this easier is to generate an array of holiday dates for the given year. After that, many languages can simply check if the date exists in the holiday array.
Also, keep in mind that some months can have up to 5 instances of a given weekday, and that some holidays are on the last instance of a weekday.
Bonus
You’ve been told that it is your job to add Easter Sunday and Good Friday into that mix. This script might be running for decades, so find some way to calculate those holidays. You might be able to connect to an online source for that, or you could try and mathematically deduce the moon’s phase from an arbitrary year. I just copied the next 10 years’ worth of dates, but I’m sure there are plenty of folks out there smarter than me who can figure it out.
22:03 UTC
[Easy] Typing Speed Test
Description
Let's make a console game where the user types words as fast as they can.
First, choose 30 words. For example,
John thinks apples spawn on binary trees in the summer moonlight despite evidence of discerning tastes among disciples ordering oranges during home advantage games allowing optimism or banana eating behavior
These can be hard-coded. Case-sensitivity is optional.
Shuffle the words and print them, space-separated. The user will type them in as fast as possible. Time the user's input.
Output
If the user types the correct string, print their WPM, to at least one place after the decimal point.
Score: 88.2 WPMIf something doesn't match, tell them they failed.
Words don't match.
Bonus
Keep track of the high score, and print it out at the end of a run.
High score: 91.5 WPM22:45 UTC
[Easy] Longest Collatz Cycle with 64 Bit Numbers
Description
Take any positive natural number n. If n is odd, the next number is 3n+1. If n is even, the next number is n/2. These rules generate Collatz sequences. The Collatz Conjecture is that, no matter what number you start with, the Collatz sequence will always reach 1.
As an example, let's start with 5.
5 -> 16 -> 8 -> 4 -> 2 -> 1This sequence has length 6.
Challenge
Your challenge today is to find the longest Collatz sequence you can find, in which no element goes above UINT64_MAX. Print out the starting number and the length.
Edit: I have found up to
18054775210080955120 1580How high can you get?
04:39 UTC
[Easy] How many people in the pie chart?
Should you trust the data in this dog pie chart? The percentages are all suspiciously round numbers. In fact, they're all integer multiples of 1/40, so probably only 40 dogs took that survey.
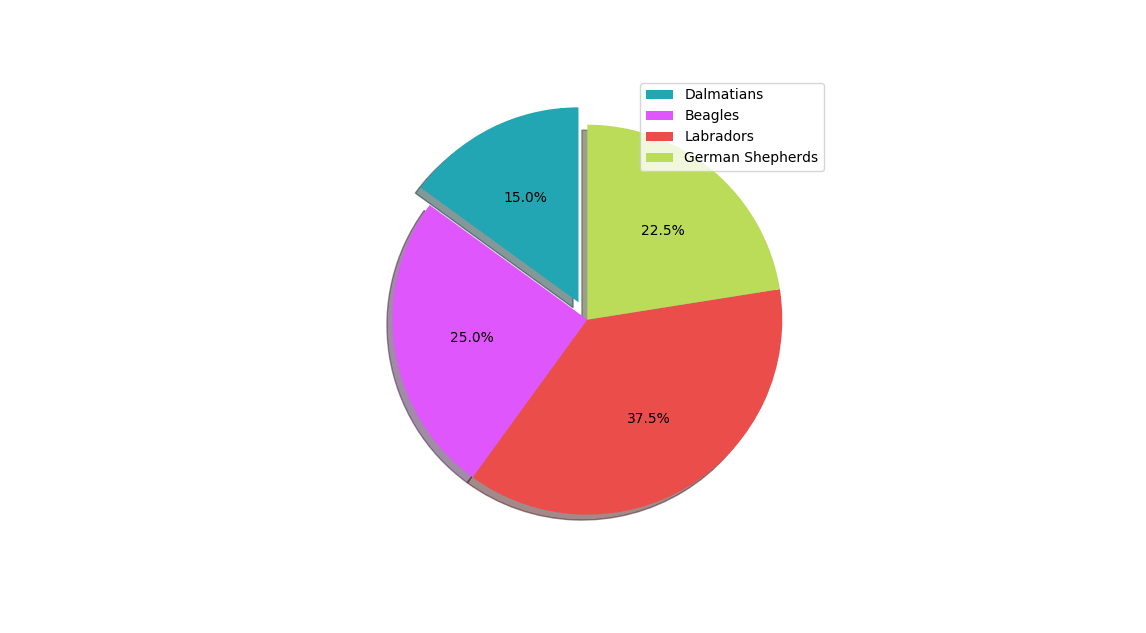{kind=link}
Challenge
Given a pie chart labeled with decimal percentages, determine its minimum possible sample size. You can write your own algorithm, or use the scaffolding below.
Warm-up 1
Write a function roundFrac(k, n, decimalPlaces) that determines the value of k/n, rounded to decimalPlaces many digits. For example, roundFrac(3, 7, 3) should return 0.429.
Steps
A pie chart percentage of 33% = 0.33 could indicate a sample size of 3. But a pie chart percentage of 0.330 could not. Write a function possibleSampleSize(sampleSize, decimalPlaces, decimalResult) that answers this question: if sampleSize people fill out a pie chart, and the results are rounded to decimalPlaces digits, could decimalResult appear in the final pie chart?
Your program could determine this by checking all possible fractions of the sampleSize. For a challenge, try to find a more efficient method.
possibleSampleSize(3, 2, 0.33) --> True
possibleSampleSize(7, 3, 0.429) --> True
possibleSampleSize(3, 4, 0.6666) --> False
Challenge input: possibleSampleSize(5890485908, 10, 0.3986299165) --> FalseNow, write a function minimumSampleSize that solves the overall challenge. The only difference is that you need to check all the decimals that appear in the pie chart, not just one.
minimumSampleSize(decimalPlaces=3,
decimals=[0.150, 0.225, 0.375, 0.250]) --> 40Test inputs
Can you guess the number of people who use Python in this survey?
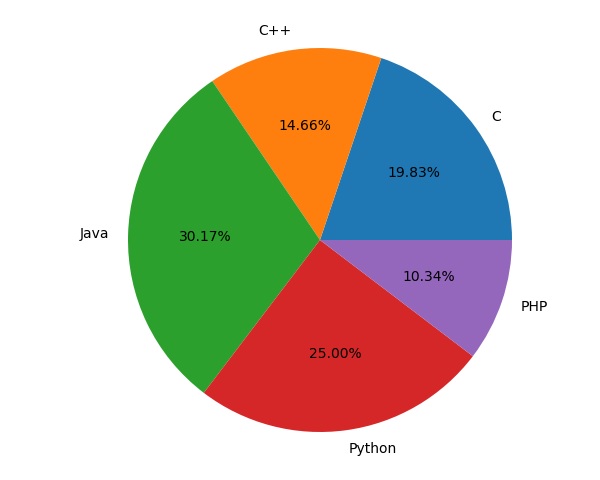{kind=link}
Do you think more male bronies or more female bronies filled out this this best pony survey?
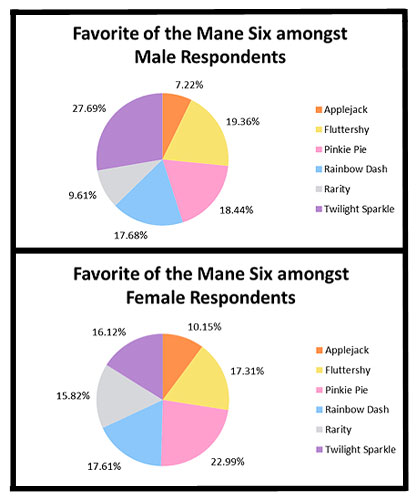{kind=link}
Bonus Challenge 1
Imagine a pie chart with 20 slices all labeled 5%. Your program probably indicates that the minimum possible sample size is 19, because 1/19 rounds to .05. But that's impossible! You can't get 20 slices with only 19 people.
Fix this problem. (It's more complicated than just stipulating that there must be at least as many people as slices.)
Challenge input: a pie chart with 40 labels of 1%, and 25 labels of 2%.
Bonus Challenge 2
For the best pony survey, I'm fairly confident in my guess for the number of female respondents, but not at all confident in my guess for the number of male respondents. Can you quantify this? I don't know a good answer to this challenge.
19:55 UTC
[Easy] The Spanish ID Inquisitor
Challenge
The Spanish National ID Document number (DNI) consists of eight digits and a letter for control purposes. The Spanish ID Inquisitor needs to check whether a given ID is valid or not.
Letters I, Ñ, O and U are excluded to avoid confusion with other characters, therefore only 23 letters are used.
The letter is determined by the remainder obtained by dividing the Id number by 23 and following the table:
| T | R | W | A | G | M | Y | F | P | D | X | B | N | J | Z | S | Q | V | H | L | C | K | E |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 |
Can you write a validator to help the Spanish Id Inquisitor?
Examples
isValid(12345678Z) => true
isValid(87654321X) => true
isValid(00000001A) => false
isValid(43685091H) => true
isValid(59357941G) => falseBonus
Number 13 was never issued due to superstition while number 15 was given to king Felipe VI of Spain. Which letters match those numbers?
15:43 UTC
[Intermediate] A meta daily programmer scraper
Description
Johnny loves programming but sadly, by day all he does is replace ink toner cartridges and waste time at his desk. His bosses have forbidden him from any means of bettering himself and visiting Reddit is strictly forbidden.
Johnny does however use an antiquated PC to fulfill all of his orders for more ink... It's entirely terminal based and is connected to the outside world.
Surely there's a way for Johnny to improve his programming skills? Perhaps by using a terminal program that scrapes dailyprogrammer? Wouldn't that be convenient?
#Formal Inputs & Outputs
##Input description
Input is given on the command line.
Examples of usage (program is assumed to be called dp):
# Downloads challenge #200, the easy one
> dp 200 easy
# Downloads all variants of challenge #200 (easy, intermediate, hard)
> dp 200
# Downloads all easy challenges
> dp all easy
# Download easy and intermediate
> dp all easy,intermediate
# Invalid ID
> dp 45869
Challenge number 45689 does not exist##Output description
The program should output a readable (not just a HTML dump) version of the challenge.
#Notes/Hints
There are some great utilities for scraping the web.
- Beautifulsoup for python
- pup for the shell
and many more
Bonus
- Create this without using the reddit API
#Finally
Have a good challenge idea?
Consider submitting it to /r/dailyprogrammer_ideas
09:14 UTC
[easy] Two sum
Description.
Given are a list of numbers (sorted from lowest to highest) and a target number. Find the two numbers from the list which, when added together, are as close to the target as possible.
Input.
An array of numbers and a target. The array is sorted from smallest to largest. Examples:
[1.1, 2.2, 3.3, 5.5], 4.3
[2, 3, 7, 11, 15], 23Output.
The pair of numbers from that array that comes closest to the target when the two numbers in the pair are summed. Examples:
1.1, 3.3
7, 1519:31 UTC
[Intermediate / easy] basic operations with roman numerals
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
Symbol Value
I 1
V 5
X 10
L 50
C 100
D 500
M 1000For example, two is written as II in Roman numeral, just two one's added together. Twelve is written as, XII, which is simply X + II. The number twenty seven is written as XXVII, which is XX + V + II
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
- I can be placed before V (5) and X (10) to make 4 and 9.
- X can be placed before L (50) and C (100) to make 40 and 90.
- C can be placed before D (500) and M (1000) to make 400 and 900.
Input & Output
your program take a string containing 2 roman numerals and a operator ("+","-","/","*") and output the result for example.
romanNumerals("II + IV") => 6
romanNumerals("V - I") => 4
romanNumerals("II * IV") => 8
romanNumerals("V / I") => 5Bonus
In you program you can do basic operations with only 2 roman numerals what if it was more then 2?
your program take a string containing 2 or more roman numerals and a operator ("+","-","/","*") anc output the result for example.
romanNumeralsBonus("II + I + V") => 8
romanNumeralsBonus("I / II + I") => 1.5
romanNumeralsBonus("II * V + V") => 15
romanNumeralsBonus("D - C * II") => 300
thanks to /u/alexwawl for inspiring this challenge !
^(btw my english is trash if I have mistake plz let me know!)
18:14 UTC
[MEDIUM] Advanced Cricket Scorekeeper
#Description
This project builds upon the cricket scorekeeper, created here: https://www.reddit.com/r/dailyprogrammer_ideas/comments/cz2xbg/easy_cricket_scorekeeper/ It will use the { data inside braces } to create a more detailed scoresheet, so make sure you've completed the bonus challenges.
The aim to create a sheet like this one: https://www.bbc.co.uk/sport/cricket/scorecard/ECKO44040
#Formal Inputs & Outputs
##Input description
The inputs will be the same as the previous challenge (linked above), but for this challenge we will parse the metadata too.
This describes messages you may receive inside the braces, and how to interpret them.
Any message in braces that is not understood should be ignored without creating an error. If a message in braces is only partially understood, it should parse the bits it can understand and ignore the bits it cannot understand.
At the start of the innings, a message will be sent with the name of the batsmen starting. It will look like this:
{ 1st-in: [name]; 2nd-in: [name] }. You may assume that names do not have any spaces in them. The 1st-in batsman starts on-strike (i.e. the bowler bowls to them, and the 2nd-in batsman starts at the bowler's end).After each wicket, metadata will be sent with information about the wicket. It will look like this:
{ Out: [Name]; How: "[method]" }. This will give the name of the batsman out, and how they got out "e.g.lbw, orc&b. Archer, orrun out.After that message, a message will be sent with either: the name of the next batsman in the format
{ NextIn: [name] }; or a message to indicate the end of the innings:{ AllOut }.At any point, the innings may be ended by the batting team declaring. This looks like this:
{ Declares }.
##Output description
At the end of the innings, print the full match score. This will require keeping track of who is on-strike. Of the two batsmen in, they change ends with every run they score (not including the run for a wide or for a no-ball), and they also change ends at the end of every over.* By carefully tracking the number of runs made, and the overs it should be possible to correctly attribute runs to the correct batsman.
Runs are attributed to the batsman on-strike except for: the single run for a no-ball; any runs scored on a wide; any runs marked "bye" or "leg-bye".
*This isn't strictly true: it is in fact the bowlers who change ends and the batsmen stay where they are.
#Bonus
The format can be extended at will, and all interpreters should be able to read the output. (Remember how they are required to ignore anything they can't interpret?) So come up and implement:
Include fall-of-wicket stats.
A way to track bowler stats. (E.g.: { Bowling: [name] } at the start of every over.)
A way to handle injury replacements, concussion substitutions, and returning after an injury.
A way to handle penalty runs awarded to the bowling team.
Error checking and recovery: detect, for example, when a batsman not on-strike gets bowled out, or a batsman who isn't in gets out.
A fancy GUI so each ball can be recorded with just a few clicks.
#Finally
Have a good challenge idea?
Consider submitting it to /r/dailyprogrammer_ideas
15:31 UTC
[EASY] Cricket Scorekeeper
#Description
This program takes the ball-by-ball report of a cricket match from the input, and converts it into match summary.
#Formal Inputs & Outputs
##Input description
Input comes from stdin. Each entry is whitespace delimited and represents one delivery. The entries that you may recognise are:
Recognised inputs are:
Any positive integer - that many runs scored off the bat. - zero runs scored+ - wideo (that is the letter O, not the digit 0) - no-ballw - wicketb - byel - leg bye
These results can be combined by putting them together. For example: +2w means there was a wide, two runs were scored, and there was a wicket.
The only input that can't be combined with anything else is ..
##Output description
The program should regularly issue a short output, in the form of [runs]-[wickets] ([overs].[balls])
The [runs] parameter is the total of runs scored, plus 1 for every wide (+), plus 1 for every no-ball (o). These are in addition to extra runs: o4 adds 5 to the team's total.
The [wickets] is a simple count of the number of w symbols.
The [overs].[balls] bit counts legal deliveries. Every ball delivered increments the [balls] counter, unless it is a wide or a no-ball.
Six legal deliveries make an over, so when the [balls] counter reaches six it should be reset to 0, and the [overs] counter incremented. You may omit the .[balls] bit if [balls] = 0 (e.g. (12.0) may be displayed as simply (12)).
#Notes/Hints
Some useful information on cricket scoresheets is here: http://www.snitterfieldcricketclub.co.uk/page.php?page=scoring
Some helpful information on cricket in general is here: https://www.keithprowse.co.uk/news-and-blog/2018/08/07/how-the-cricket-scoring-works/
Some unhelpful information on cricket is here: https://www.melcarson.com/rules-of-cricket-simplified.html
#Bonus
For future-compatibility, we may want to add meta-data. To support this, if you find a { symbol, ignore input until you reach a }. Future versions of this may parse the contents of these brackets.
Also, at the end of an innings (i.e. when wickets reaches 10), print a summary along the lines of:
Runs : nnn
No-balls: nnnn
Wides: nnnn
Byes: nnnn
Leg-byes: nnnnn
Total extras: nnnn
Total score: nnnn#Finally
Have a good challenge idea?
Consider submitting it to /r/dailyprogrammer_ideas
10:17 UTC
[easy] Are all brackets matching?
Given a piece of text, discover whether all opening brackets have a corresponding closing bracket after it.
- There are 4 types of brackets: (, [, { and <. Each of these opening brackets must be closed by the corresponding closing bracket: ), ], } and >.
- Each closing bracket must have a corresponding opening bracket in front of it.
- If an opening bracket A comes before opening bracket B, B must be closed before A.
- All text that are not brackets, can be ignored.
Input description
A string.
Output description
A boolean, which is true if all requirements above are satisfied.
Examples:
"This is a text without brackets" --> True
"()[]{}<>" --> True
"not clo(sed" --> False
"[s(o{m(e( <w>o)r)d}s)!]" --> True
"Closed}be4{opened" --> False
"[<]>" --> False08:14 UTC
[Easy] Yahtzee scoring
#Description
Yahtzee is a dice game where the objective is to score points by rolling five dice to make certain combinations.
The Yahtzee scorecard contains 13 different category boxes and in each round, after rolling the five dice, the player must choose one of these categories. The score entered in the box depends on how well the five dice match the scoring rule for the category.
The categories and their corresponding scores are as follows:
| Category | Requirement | Score | Example |
|---|---|---|---|
| Aces | Any combination | Sum of dice with the number 1 | [1-1-1-3-4] scores 3 |
| Twos | Any combination | Sum of dice with the number 2 | [2-2-2-5-6] scores 6 |
| Threes | Any combination | Sum of dice with the number 3 | [3-3-3-3-4] scores 12 |
| Fours | Any combination | Sum of dice with the number 4 | [4-4-5-5-5] scores 8 |
| Fives | Any combination | Sum of dice with the number 5 | [1-1-2-2-5] scores 5 |
| Sixes | Any combination | Sum of dice with the number 6 | [2-3-6-6-6] scores 18 |
| Three Of A Kind | At least three dice the same | Sum of all dice | [2-3-4-4-4] scores 17 |
| Four Of A Kind | At least four dice the same | Sum of all dice | [4-5-5-5-5] scores 24 |
| Full House | Three of one number and two of another | 25 | [2-2-5-5-5] scores 25 |
| Small Straight | Four sequential dice | 30 | [1-3-4-5-6] scores 30 |
| Large Straight | Five sequential dice | 40 | [2-3-4-5-6] scores 40 |
| Yahtzee | All five dice the same | 50 | [1-1-1-1-1] scores 50 |
| Chance | Any combination | Sum of all dice | [1-1-3-3-5] scores 13 |
In this challenge, given a set of five dice values, you have to output the score that each category would give (in the order of the previous table).
#Formal Inputs & Outputs
##Input description
A set of 5 unsorted integers, between 1 and 6.
##Output description
A set of 13 integer values that correspond to the scores for each scorecard category, in the order of the previous table.
Examples
yahtzee([1,1,1,1,1]) => [5, 0, 0, 0, 0, 0, 5, 5, 0, 0, 0, 50, 5]
yahtzee([3,5,2,4,5]) => [0, 2, 3, 4, 10, 0, 0, 0, 0, 30, 0, 0, 19]
yahtzee([2,5,2,2,5]) => [0, 6, 0, 0, 10, 0, 16, 0, 25, 0, 0, 0, 16]
yahtzee([1,2,5,4,1]) => [2, 2, 0, 4, 5, 0, 0, 0, 0, 0, 0, 0, 13]13:17 UTC
[Intermediate] Morse Code Translator
Description
In this challenge you need to translate text to morse code! for for example:
"Hello world" in morse is:
.... . .-.. .-.. --- / .-- --- .-. .-.. -..*important*( you separating the letters by spaces and words by '/' or '|'. )
Inputs Description
the input needs to be a text in Letters and numbers only!
Output description
MorseCode("hi") => .... ..
MorseCode("this is morse code") => - .... .. ... / .. ... / -- --- .-. ... . / -.-. --- -.. .
MorseCode("123hello123") => .---- ..--- ...-- .... . .-.. .-.. --- .---- ..--- ...--
MorseCode("1234567890") => .---- ..--- ...-- ....- ..... -.... --... ---.. ----. -----Notes
Bonus
adding punctuation marks like '!' , '.' , '?'
for example:
MorseCode("hi!") => .... .. -.-.--
MorseCode("hi?") => .... .. ..--..
MorseCode("hi.") => .... .. .-.-.- Bonus output description
MorseCode("this is good!") => - .... .. ... / .. ... / --. --- --- -.. -.-.--
MorseCode("ok.") => - .... .. ... / .. ... / --. --- --- -.. -.-.--
MorseCode("where are you?") => - .... .. ... / .. ... / --. --- --- -.. -.-.--
this is my first time posting here if i have any mistake please let me know!
13:36 UTC
Meta: what I look for in a r/dailyprogrammer_ideas submission
Someone asked the moderators whether r/dailyprogrammer_ideas is still used. I can only speak for myself, but I'm the only one posting recently for what it's worth. But I know that other moderators care about different things than me.
The short answer is that I do read it for inspiration, but I rarely get ideas from there. The main reason is that I look for certain things in a challenge, and, partly due to my own laziness, it's hard to see how to work those ideas into what I consider a good challenge.
So what do I look for? It's different for Easy, Intermediate, and Hard, and also different if it's a standalone challenge, or a series of challenges that build on each other. Given the state of the subreddit, I'm currently focused on standalone Easy challenges, since Easy ones get by far the biggest response. So here's what I look for in a standalone Easy:
It should be expressed as a simple map from input to output (i.e. a function), dealing only with very simple data types (number, string, boolean, list). Anything like "build an app" or "parse this data set" or sound, graphics, web, etc., while interesting, is beyond the scope of Easy.
It should solve an interesting problem. Interesting can mean many things, such as a realistic problem that you might actually need to solve for a job or project, or some interesting mathematics you might see on Numberphile. But I try to avoid "exercises" where you have to solve artificial problems with no connection to any greater context. Here's a recent example where, IMHO, I failed this criterion and chose an uninteresting problem.
It should have multiple parts, and the easiest part should be very easy. If anyone posts that they don't even know how to get started, that's a failure on my part. But if it was just a very easy part, many people would get bored. So either the main challenge is very easy and there's an optional bonus, or there's a very easy warmup before the main challenge. Usually any problem can be adapted to be easier or harder, but sometimes it's more straightforward than others.
It should be fully explained. I would not post an Easy problem where the algorithm to solve it was unclear. Ideally it's clear enough that any non-coder could solve it by hand, and it's just a matter of converting that known algorithm into code. Any challenge can fit this criterion with enough explanation, but too much explanation makes the challenge unwieldy.
So that's it. I read through high-rated Easy challenges on r/dailyprogrammer_ideas and skip them for one of those reasons.
But I'm sure there's also a lack of imagination on my part. I'm sure that many ideas I skip could be made into what I'm looking for with a little work. If you have an Easy challenge you want posted, and you're willing to spend a couple hours working with me to get it ready, PM me the link and I'll take a look and tell you what I think it needs.
23:34 UTC
[META] Subreddit status
Just wanted to see if this subredddit and its parent are still considered active or if the cadence has changed?
It appears that there is now one challenge a month. Is that intentional or just a result of the activity?
Great subreddit and I really appreciate the wealth of challenges that have come up here.
20:08 UTC
The 24 Game
Description
The 24 game is a simple game where you are shown a card with 4 numbers on it (can be duplicates). The aim is to make the number 24 using all 4 numbers only once and any number of the 4 basic operations (add, subtract, divide, multiply). write a program that takes 4 numbers as an input, and outputs any solutions there are to the problem.
Input description
A very simple one would be 24, 1, 1 and 1
Output description
in this case the program would output:
24 + 1, 25 - 1, 24 * 1
24 * 1, 24 * 1, 24 * 1
1 * 1, 1 * 1, 24 * 1
Bonus
Trying to add more operations like powers or roots or increasing the number of inputs to allow the user to decide what the answer should be. So would input "10, 10, 10, 10, 40" meaning the program should make 40 using 4 10's
00:04 UTC